

根据32楼mjj提醒, 使用http.cliens是可以正常获取页面的, 但是使用requests就不行了, 用的同一套 proxies和headers....,有大佬一起研究下是什么原因吗?我就想用requests来爬
-------------------------------------------------------------------------------------------------
最近想冲刺一下考研, 所以就上去P站看考研的视频(咳咳咳)
使用python获取网页源码的时候发现用re匹配不到结果
最后我把python爬下来的内容用浏览器打开看看,发现直接提示
no valid source are available for the video
了, 加了cookie和UA也是一样, 代理和浏览器用的是同一个, mjj有啥解决思路嘛?
地址: cn.po删rnhub.com/view_video.php?viewkey=ph620dd32bd1ec4
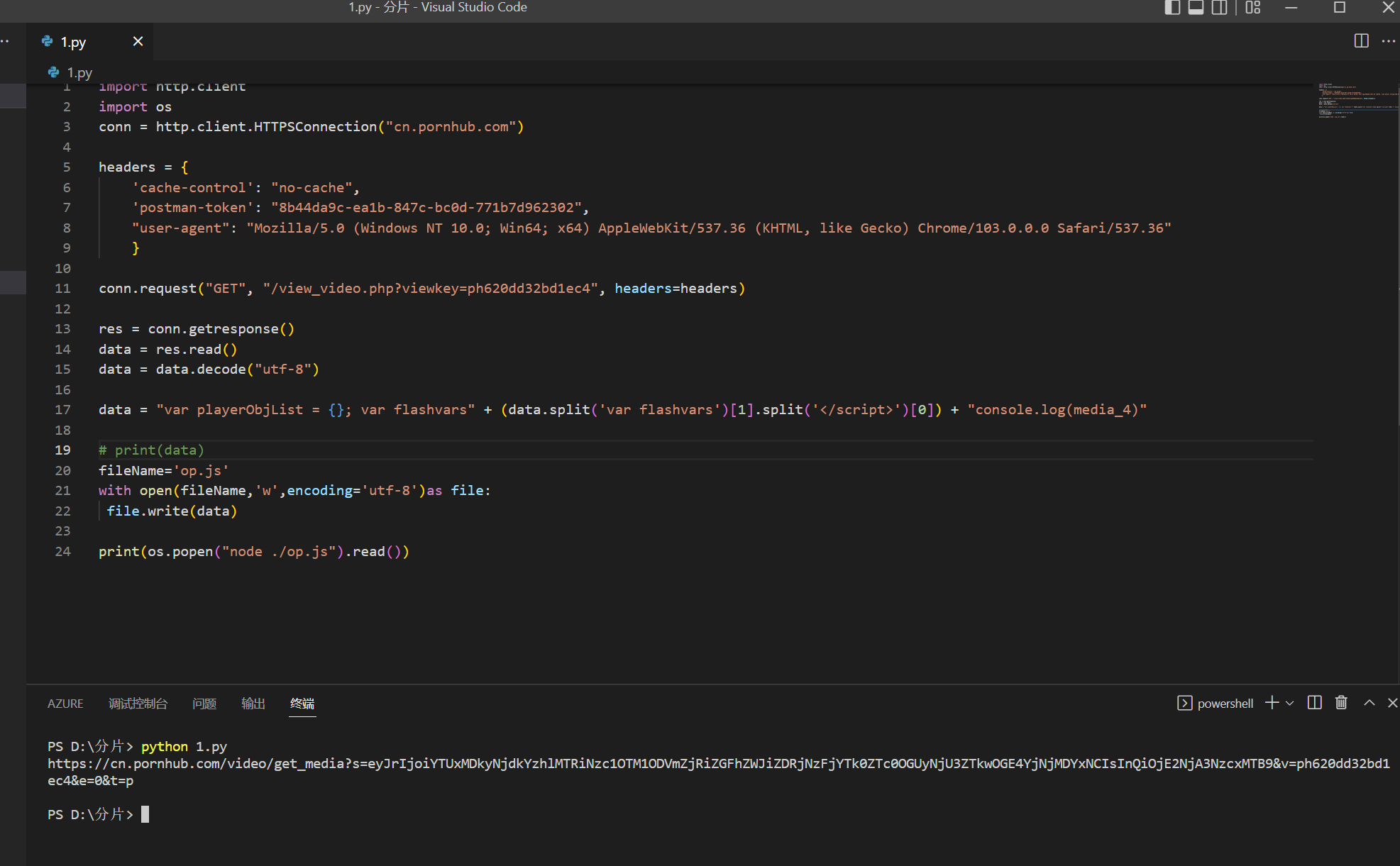
p站程序员把mp4完整视频的链接放在了html页面里并赋值为 media_4,只要把这个值提取出来就可以拿到视频完整直链(非m3u8切片), 但是现在请求下的页面有问题, 找不到这个值, 这个值不是由JS生成的,是直接放在html页面的

正常的返回网页结果应该有 media_4 这个关键词的
用python的话返回时这个样子的

-------------------------------------------------------------------------------------------------
我用python请求返回来的是张这样的, html页面开头有好几行注释, 正常的不应该会有这么多注释

热议
推荐楼 hous135 前天13:05
换个姿势,用selenium 或者puppeteer
3楼 Unique 前天13:08
2楼正解,稍微有点反爬的re处理都比较麻烦
4楼 dragonfsky 前天13:30
大概率是js加载的数据 直接上selenium
5楼 Mr.lin 前天13:33
selenium多慢啊, 要是js渲染的就去解这个js
6楼 CapitalTeemo 前天14:54
js逆向
7楼 榆榆不可及 前天15:00
虽然 我不会
但是你这个提问方式我就很喜欢
8楼 Tankie 前天15:10
selenium多慢啊, 要是js渲染的就去解这个js
这个是大佬,我梦想着自己的JS能到这个水平
9楼 深海空间 前天15:50
大概率是js加载的数据 直接上selenium
感觉不是通过JS加载页面的, 我在chrome上右键查看源代码时是可以看到哪些内容, 通过xhr加载的话源代码看不到的
10楼 深海空间 前天16:36
selenium多慢啊, 要是js渲染的就去解这个js
不是JS渲染的, 关键信息都放在这个路径的html页面里
12楼 深海空间 前天18:37
现在最流行的姿势是用golang的chromedp库实现~
就学了python, go没接触过...
13楼 遥远彼方 前天18:41
楼上说的正解,你能看到是一致的只不过是已经JS处理过了
14楼 dragonfsky 前天19:06
感觉不是通过JS加载页面的, 我在chrome上右键查看源代码时是可以看到哪些内容, 通过xhr加载的话源代码看 ...
pm 网页 我也瞅瞅
15楼 dragonfsky 前天19:07
现在最流行的姿势是用golang的chromedp库实现~
大佬 这玩意可以过cf的机器人识别吗selenium会自己暴露特征 搞半天都过不了cf
16楼 深海空间 前天19:33
楼上说的正解,你能看到是一致的只不过是已经JS处理过了
我是在chrome里通过右键,查看网页源代码的, 这种情况下, JS应该还没生效吧
17楼 Chiser 前天19:35
如果你右键查看网站源代码没有上述关键词,那就换个姿势,或者考虑手机模式下,说不定有惊喜
18楼 jinwyp 前天20:15
换个姿势,用selenium 或者puppeteer
用selenium 或puppeteer 爬起来是不是比以前直接抓页面慢很多?
19楼 jinwyp 前天20:16
selenium多慢啊, 要是js渲染的就去解这个js
这啥技术? 怎么解js? 还不是需要webkit去渲染dom啊? 最后和puppteer 不是一样吗?
20楼 jinwyp 前天20:23
现在最流行的姿势是用golang的chromedp库实现~
这个比Puppeteer快多少? 但这个还是和Puppeteer一样啊
Puppeteer可是官方的啊
22楼 badyun 前天21:06
应该没区分啊,我用postman直接get都有
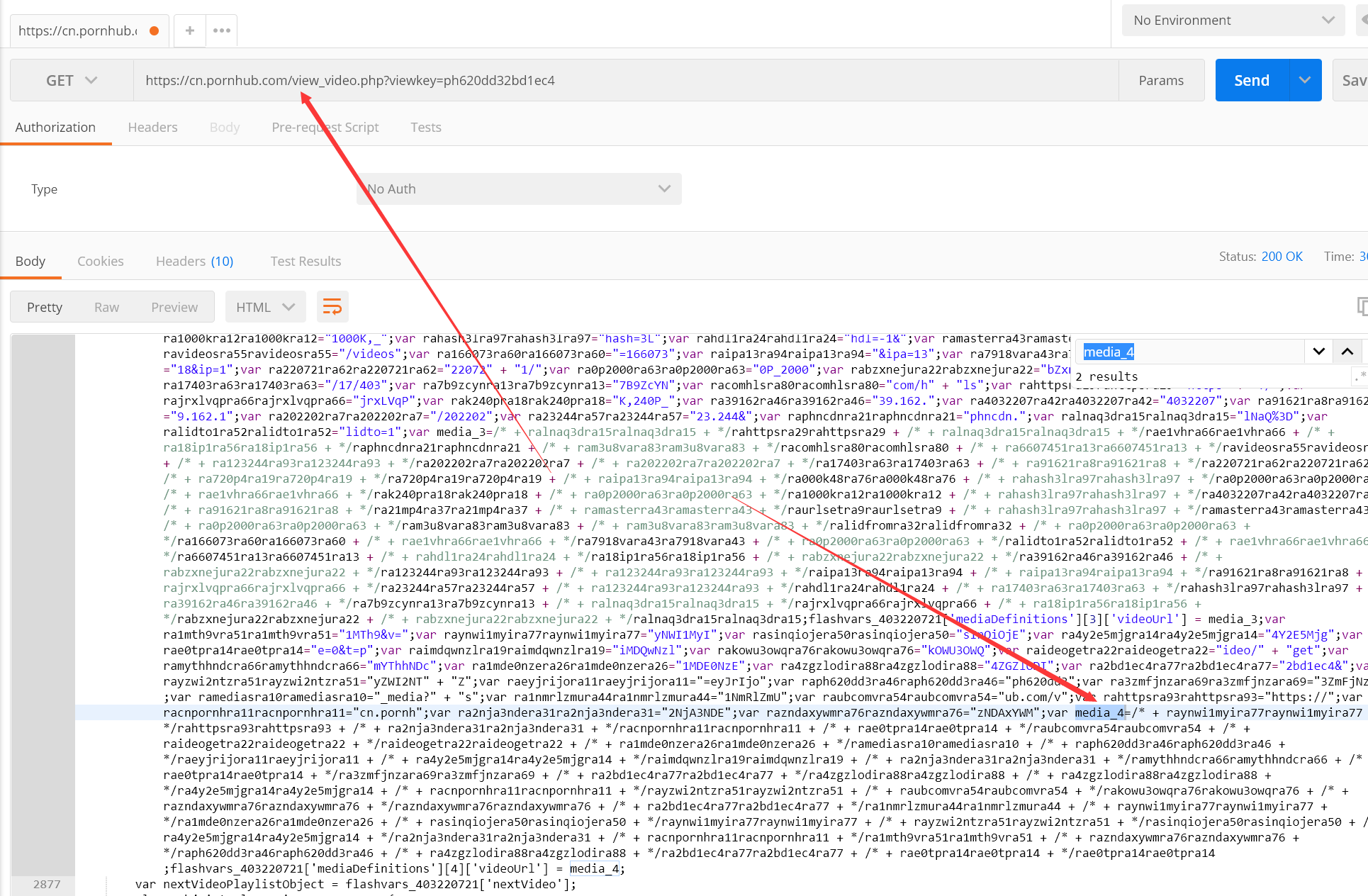
23楼 深海空间 前天22:25
应该没区分啊,我用postman直接get都有
我用python的话
24楼 委员 前天22:28
真考研不会去扒视频的 ,看书才是王道。
25楼 红A 前天23:06
是js计算的,需要把动态生成的那段js运行一下,就能得到m3u8地址
26楼 深海空间 前天23:29
是js计算的,需要把动态生成的那段js运行一下,就能得到m3u8地址
不是, 你打开我帖子里的链接, 再打开chrome调试工具, 刷新页面, 然后在console里打印media_4这个值, 这个是写死在html页面的一个mp4格式的直链(非m3u8切片)
27楼 teardrops 前天23:42
用python试了下. 抓回来的 源码有 media_4
你确认下get 发出的http头吧
28楼 wjj 前天23:49
postman直接调都有,肯定不是js算的
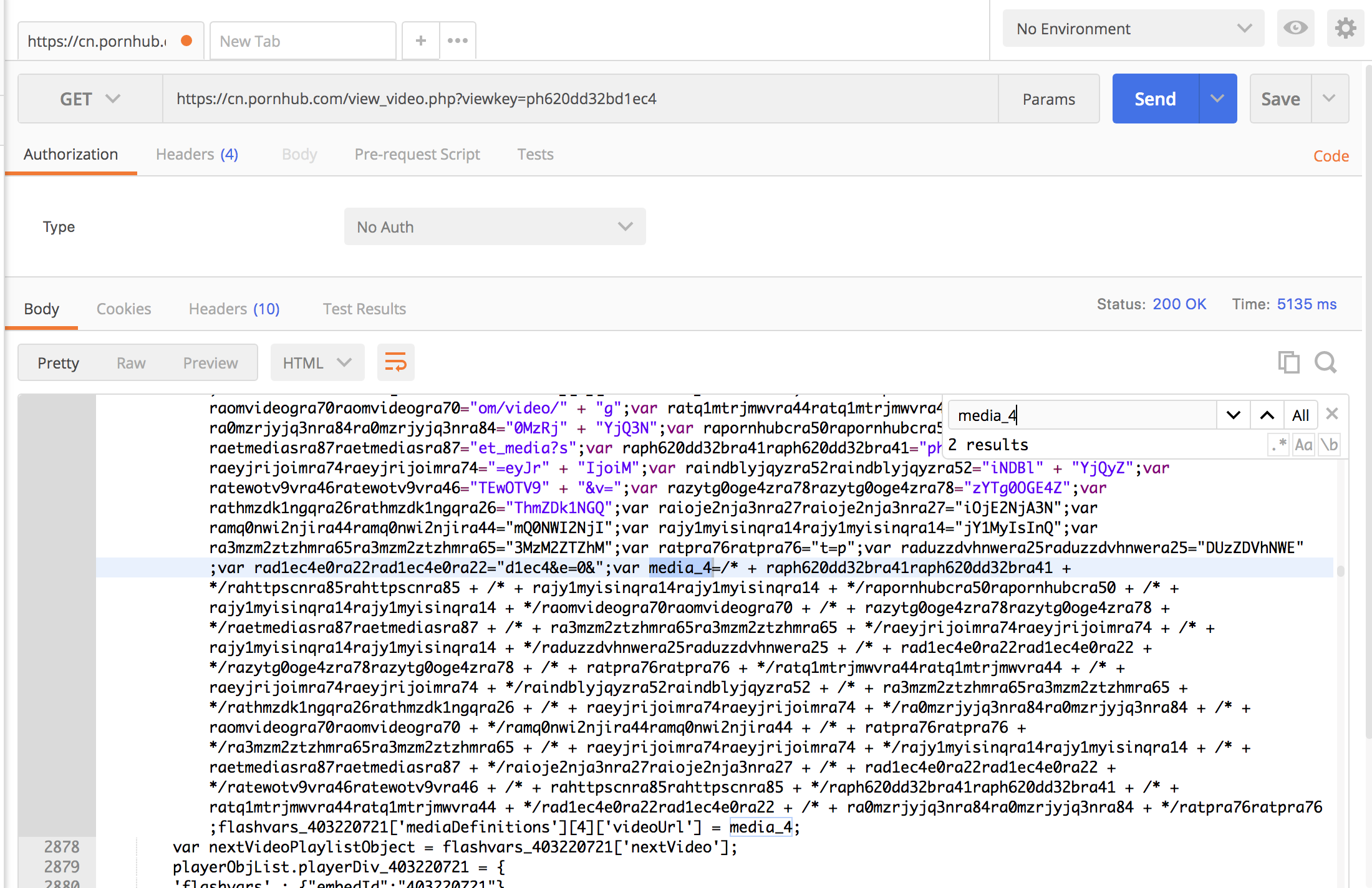
29楼 深海空间 昨天00:18
用python试了下. 抓回来的 源码有 media_4
你确认下get 发出的http头吧
见鬼了, 就两行代码, 不应该会出错的啊
30楼 hous135 昨天00:26
深海空间 发表于 2022-8-18 00:18
见鬼了, 就两行代码, 不应该会出错的啊
请求头问题吧……
32楼 badyun 昨天06:59
我用python的话
我用py试了一遍,没问题啊
33楼 Mr.lin 昨天11:40
确实有点坑, 他的开发者和他的网站一样骚
但是这里存在一些小技巧, 甚至headers都是多余的, 它的检测点不在这里

34楼 深海空间 昨天12:45
我用py试了一遍,没问题啊
确实, 用你的方法使用http.client可以获取到正常的页面, 但是用requests库就不正常了, 你用requests也测试一下
35楼 深海空间 昨天12:46
确实有点坑, 他的开发者和他的网站一样骚
但是这里存在一些小技巧, 甚至headers都是多余的, 它的检测点不在 ...
老哥说一下, 问题出在哪里? 我已经想不到了, 用http.client是正常获取的, 但是用requests就不行了
36楼 deyu 昨天17:24
学习了,明天晚上我也去试试,还有你用得那个软件是什么写代码的软件,用记事本写太累了
37楼 深海空间 昨天17:30
学习了,明天晚上我也去试试,还有你用得那个软件是什么写代码的软件,用记事本写太累了 ...
我用的 sublimetext, 我就图个启动快速, 如果正常开发的话, 建议用vscode
38楼 zqm840527 昨天19:30
playwright好像是selenium的升级版
39楼 遥远彼方 3小时前
我是在chrome里通过右键,查看网页源代码的, 这种情况下, JS应该还没生效吧
你能用控制台看早就生效了,下个插件可以组织JS加载的看看。
40楼 深海空间 3小时前
你能用控制台看早就生效了,下个插件可以组织JS加载的看看。
去看33楼,他用requests get下来了,不过他似乎没打算说咋搞的。。。,应该是被检测到用requests所以返回了假的页面html给我
42楼 inighty 2小时前
我这没这个问题随便就能请求是因为代理的原因吗
![]()

43楼 深海空间 1小时前
我这没这个问题随便就能请求是因为代理的原因吗
有毒,你跑一下我这段代码试试,不像是代理的问题,因为我用chrome是可以正常请求页面的。
https://notepad.pw/4asps27f
44楼 inighty 13分钟前
有毒,你跑一下我这段代码试试,不像是代理的问题,因为我用chrome是可以正常请求页面的。
https://note ...
我没有http代理![]()
申明:本文内容由网友收集分享,仅供学习参考使用。如文中内容侵犯到您的利益,请在文章下方留言,本站会第一时间进行处理。